

This article discusses the distinctions between the old and new Microsoft Office file formats, and explains the advantages of choosing the new formats, which are called the Office Open XML file formats. Confusingly, the Office Open XML formats are not the same as the OpenOffice XML file formats. The naming similarity causes much confusion, and arises from the fact that the goals of both definitions were similar, even though the implementations are distinct.
This article also explains how you can decompress a Word file that has been stored using the new XML format and examine its content directly. This can sometimes be helpful if you find that you cannot open a file because it has been corrupted, in which case you may be able to fix the error and make the file once again editable.
In an earlier post, I mentioned the new file format for Microsoft Word files (i.e., files with a .docx extension), which stores data using XML, instead of the binary data coding that was used by the original Microsoft Word format (files with a .doc extension). In fact, that is true not only for .docx files, but also for various other file types created using recent versions of Microsoft’s Office suite of programs. For example, Microsoft Excel files have a new .xlsx format, replacing the older .xls format.
In my earlier post, I also mentioned the general dangers of using proprietary file formats (for any application), because the data contained in the files can only be accessed via the one specific application that’s designed to open files in that format. If the application becomes unavailable, or if the manufacturer changes the program to the point where it is no longer able to open files that use its own older formats, you may have no way to access data in files with the proprietary format. This could result in a severe loss of data at some future time.
To avoid this situation, it’s better whenever possible to store data using open file formats.
Just in case you think that, by extolling the advantages of the Office Open XML file formats here, I’m acting as a “shill” for Microsoft, rest assured that I’m not. In fact, if you read on, you’ll discover why using these new formats can actually free you from dependence on Microsoft’s applications.
Office Productivity Suites
Over the years, it has become apparent that certain types of application program have widespread usefulness in office environments across many industries. The exact list varies, but in general the following program types are used by typical office computer users:
- Word Processor
- Spreadsheet
- Email Client
- Slide Show Generator
- Vector Drawing
Software manufacturers have grouped together these commonly-used programs, and offer them as “office productivity suites” with varying levels of integration between the component programs within the suite.
Most computer users will be aware that the Microsoft Office suite is still the most widely-used office productivity suite in the world (see, for example, http://www.cmswire.com/cms/document-management/microsoft-office-is-still-the-productivity-suite-leader-022908.php).
The continued popularity of Microsoft Office is perhaps surprising, because the software is by no means free, and in fact there are good-quality free alternatives available. In this article, I won’t discuss the psychology of why so many people continue to pay to use a piece of software when there are equivalent free alternatives available. However, I will mention some of the alternatives, and show you how the Open XML file formats allow you to use those more easily.
Incidentally, it’s not my intention in this article to discuss the general use of Office suite software in “IT” environments. I don’t work in the field of “IT” (in the sense that the term is typically used), but I do use Office suite software in my roles as author and programmer.
Why were the XML Formats Developed?
I haven’t found any clear statement of the motivation that prompted Microsoft to consider replacing its long-standing binary file formats with XML-based formats. However, I suspect that the primary motivations were competition and pressure from large users of the Office suite.
Given the prevalence of Microsoft Office on computer systems around the world, around the year 2000, many government and official bodies were becoming concerned about the amount of vital information that was being stored in files using the Microsoft binary formats. The problem wasn’t merely the risk that files could become corrupt or unreadable. There was also concern that it was impossible to be certain that the proprietary data formats didn’t include “back doors” that would permit the reading of content that was supposed to be secure.
At the same time, open-source software was being developed to provide free alternatives to the more popular applications in the Microsoft Office suite. The most prominent of these open-source suites was OpenOffice, developed by Sun Microsystems. Although OpenOffice supported the Microsoft binary file formats, it also had its own set of XML-based formats, conforming to the public OpenOffice XML standards.
As a result of these developments, Microsoft offered its own version of open XML-based format specifications, and sought international certification of those formats. The result is that both sets of standards are now publicly available.
Advantages of the XML Formats
- Files are more compact. In most cases, if you compare the size of an Office file saved in the binary format, with the same file saved in the equivalent Open XML format, the XML-formatted file will be smaller. This is largely because of the compression applied to the Open XML files. However, files that contain a large number of graphics may not be smaller, because the graphics cannot be further compressed by the zip algorithm.
- Easier corrupted file recovery.
- Easier to locate and parse content.
- Files can be opened and edited with any XML editor.
- Files containing macros are easier to identify.
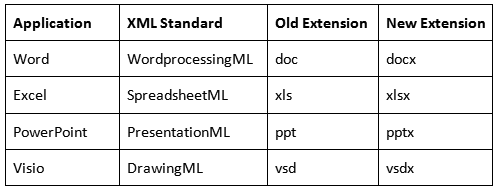
Formats & Applications
The Office Open XML formats correspond to the Office applications as shown in the table below:
How To Examine the Contents of a Word docx File
When you use Word (or an equivalent word processor) to open a file that uses one of the XML file formats, such as a Word docx file, all you see is a view of the document itself, complete with all its formatting. There seems to be no evidence of any XML structure.
If this is an XML-encoded file, then where is the XML? How do you actually access the XML that defines the document?
In fact, all files that use any of the Office XML formats compress all the XML and component parts into one “zip” file. You can, of course, compress other files into “zip” files, but, when you do, the resulting file typically has the extension .zip.
In fact, Office XML files are indeed zip files, and can have a valid .zip extension. To be able to view and even extract the internal XML and other components, you simply have to open the file using a zip extraction program, instead of a Microsoft Office program. In Windows, the easiest way to do that is to give the Office file a .zip extension.
The following procedure explains exactly how to do this under Windows. Note that this is not an “undocumented hack”; Microsoft encourages you to access the components of the documents this way. These instructions are available from Microsoft at: https://msdn.microsoft.com/en-us/library/aa982683(v=office.12).aspx
- Add a
.zipextension to the end of the file name, before the.docx - Double-click the file. It will open in the ZIP application. You can see the parts that comprise the file.
- Extract the parts to the folder that you created previously.
Non-Microsoft Support for the XML Formats
Many people seem to assume that, if they receive a file in one of the Microsoft Office file formats (either the older proprietary formats or the newer XML formats), then they must use Microsoft Office to open and edit it.
In fact, that’s not true, because the available competitor office suites can handle many of the Microsoft formats well. OpenOffice and Libre Office can both edit files in many of the Microsoft Office formats. Additionally, modern versions of Microsoft Office can at least open files in many of the OpenOffice XML formats, even if it does not fully support them. (In all cases there may be minor formatting differences, and you shouldn’t swap between formats unnecessarily.)
Thus, using the new Office Open XML file formats does not restrict you to using only Microsoft-supplied applications. Files in these formats can be expected to be reasonably “future-proof” for a long time to come.
Deficiencies of the Office Open XML Formats
I am not aware of any major deficiencies of the new formats that would dissuade anyone from using them in preference to the previous binary formats. Here are some relatively minor issues to consider:
- Some files containing large quantities of graphics may be larger than in the equivalent binary format.
- Files in the new Open XML formats cannot be opened using old (pre-2007) versions of Office.
- The XML structure is such that it’s not easy to parse the content of the files in useful ways.
Structure Example
Here’s an example of the actual Word XML markup for a very simple text document. The example shows how revisions to the markup are stored in the file, which can make it difficult to parse the XML content to extract meaningful information.
I wrote a very simple text file, which includes the line of “Normal”-styled text: “This is just a test.”.
In the WordML XML, this appears as:
<w:r><w:t>This is just a test.</w:t></w:r>
Next, I deliberately introduced a revision, by typing some extra characters before the final “t” of “test”, then deleting the extra characters and saving the result. The resulting XML looks like this:
<w:r><w:t>This is just a tes</w:t></w:r><w:bookmarkStart w:id="0" w:name="_GoBack"/><w:bookmarkEnd w:id="0"/><w:r w:rsidR="0000364D"><w:t>t</w:t></w:r><w:r w:rsidR="003F3CE4"><w:t>.</w:t></w:r>
As you can see, the final “t” and the period are now in separate <w:t> elements, and a new bookmark has been inserted. This type of element-splitting makes it difficult to extract the actual text from the XML.
Therefore, before attempting any processing of an Office Open XML-formatted file, you should always “Accept all changes” to eliminate version-tracking markup.
Recommendations
- Always use the new XML Office formats rather than the old binary formats when possible.
- Even if you have Microsoft Office installed, consider installing LibreOffice, etc., on the same computer. You’ve nothing to lose.