Screen Capture for Free!

This article describes techniques for capturing the screen image of devices using various operating systems, such as Windows, Android, Linux, etc. Most computer users don’t realize that all Operating Systems have built-in functionality to achieve this.
Even if you’re not writing computer documentation or producing artwork, the ability to capture a static image of the screen you’re viewing, or even a video, is a very useful skill. For example, you may want to capture the text of an instant message from the screen of your smartphone, to provide written proof of what messages were actually exchanged during a dispute (which you’ll need when you appear in front of Judge Judy!).
As I said, all Operating Systems have built-in functionality to achieve this, so additional tools are usually not required. However, the feature is partially hardware-dependent, so techniques vary according to the available user interface controls of the device.
I’ll also discuss a few pitfalls of the screen capture process. I’ll show you how you can reduce the size of a captured dialog image without also reducing its quality.
What is a Screen Capture?
As I mentioned in a previous post, when you’re viewing the display of any modern computer, tablet or smartphone device, you’re actually looking at a bitmap image. Therefore, surely it should be possible to copy that bitmap into a file and save it for later use. In principle this should be easy, but in practice there are cases where computer manufacturers and software developers can make it difficult, either intentionally or otherwise.
In most cases, the device’s Operating System provides built-in techniques that you can use to perform screen captures.
An example of the basic screen capture process is shown in the diagram below.
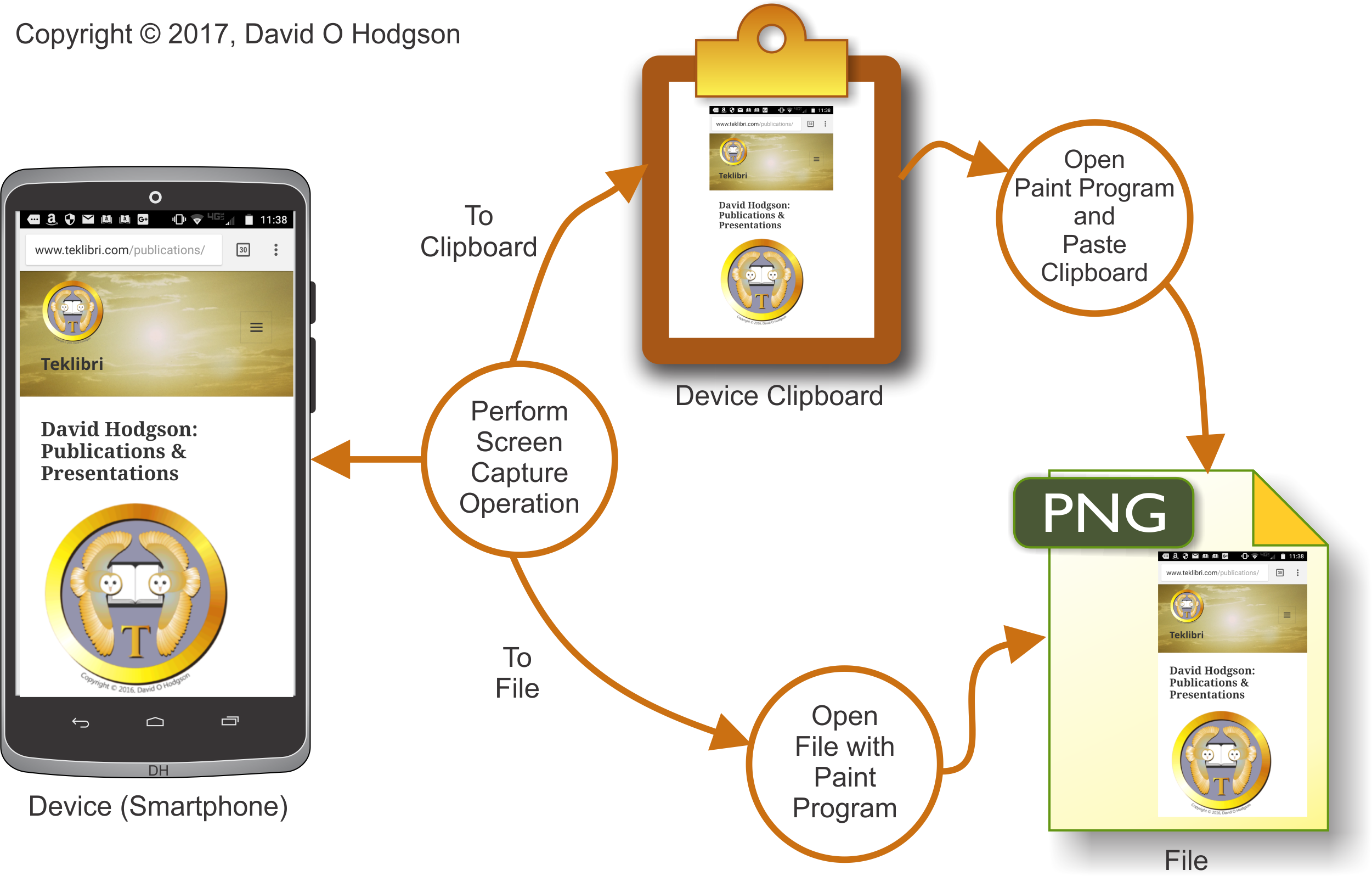
As shown in the diagram above, you perform the screen capture operation according to your device’s operating system, which copies the screen bitmap either to a file, or to an area of memory called the Clipboard. If the bitmap was copied to the Clipboard, you open a Paint program and paste it into a blank image. If the bitmap was copied to a file, you can open that file with your Paint program, as you would for any other bitmap image.
(Note: I changed the file type in the diagram above to “PNG” from “JPEG” because, as I explained in my previous post on Mosquitoes, JPEG usually is not a good format choice for saving screen capture images.)
You can also purchase third-party tools to perform screen captures, but many of these simply take advantage of users’ ignorance of the capabilities that are already built into the operating system, and hence available free of charge. Some screen capture utilities do provide additional capabilities; there’s nothing wrong with them, but it’s smart to be aware of what you can do without additional software or cost.
The Two Types of Screen Capture
There are two types of screen capture:
- Static. Grab a single bitmap image of the screen content.
- Video. Record a segment of screen activity as a digital movie.
Note that, in this article, I’m not specifically discussing the concept of capturing a frame image from a movie that you happen to be watching on your device. While you can use the techniques described here to capture such frames, it’s usually easier to use functionality provided with your video viewing software (such as, for example, Cyberlink PowerDVD).
A Little History
When I started developing Windows software, in the early 1990s, I was creating step-by-step tutorials describing computer setup, so I needed to include many screen captures. I understood what I needed to do, but I didn’t know how to do it, so I searched for screen capture tools. Several were on offer, costing from $70 upwards. However, I soon discovered that Windows came with a built-in screen capture function, which was thus available for free. You simply press the Print Screen key on the keyboard, which causes the screen image to be pasted to the Windows clipboard. Then, you can paste the clipboard image into any bitmap editing program.
Since then, I’ve spent more than a couple of decades developing software, much of which has been for some version of Windows, and it amazes me how many experienced Windows users and developers still don’t know about the Print Screen function! I see people still buying expensive commercial tools, simply to do something that their Operating System can already do.
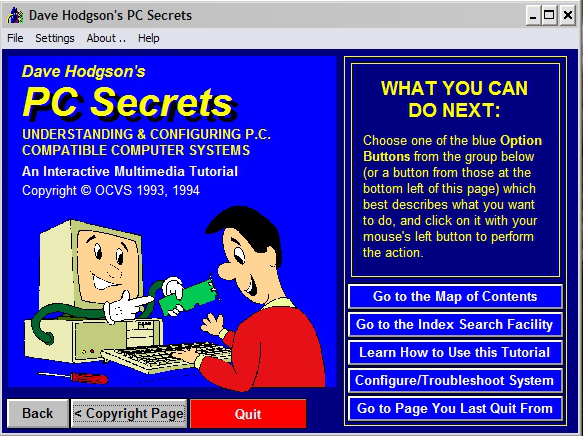
The image above shows a screen capture of the title screen of one of my early “multimedia” productions (“PC Secrets”). I admit that, with the benefit of hindsight, it looks very garish and crude! Bear in mind, though, that given the state of technology at the time, screens had to be readable on monitors that could display only sixteen colors.
Legal Issues & Image Downloading
Most people are aware of the copyright issues that attach to the copying of on-screen images. In principle, just about everything that is displayed on-screen is subject to someone’s copyright. In practice, however, copyright concerns arise only in connection with images that are regarded as having value, such as photographs or artwork.
This article describes techniques for image capture from the device’s display itself, as opposed to the downloading of images from web sites. However, since any image that you download from a web site can be displayed on your device’s screen, you can obviously use screen capture to create copies of downloaded images.
If you can see an Image, you’ve Downloaded it!
You’ll probably encounter some web sites that go to considerable trouble to try to prevent you from downloading images (typically those that display photos or artwork). This has always seemed laughable to me, because, if you’re looking at the image on-screen, then you have already downloaded it! It seems that the web site owners simply hope that their users are too ignorant to know that, or that this was a requirement specified by some manager or “marketing type” ignorant of how computer display technology actually works.
Types of Capture
Static Bitmap
This technique allows you to grab a static bitmap, containing the content of your device’s screen at one instant in time.
All modern operating systems with a graphical user interface provide a built-in means of doing this.
Video
This technique allows you to record a movie of your device’s screen. The movements of anything on the screen while you were recording will be replicated in the movie. This is very useful if you want to create a movie showing computer users how to perform a task.
Most operating systems do not include built-in video recording capabilities, but Windows 10 does now offer such a feature, as described below. If your operating system does not offer video recording capabilities, you can buy third-party tools to add the functionality.
Native Capture Capabilities by Operating System
Screen capture is an area where procedures are heavily dependent on the operating system that you’re using. For example, knowing how to perform a screen capture on a Windows PC is useless when you want to grab the screen of an Android phone. For this reason, I’ve grouped the information below according to operating system.
Note that my practical experience is mostly limited to Windows and Android systems, so, for other operating systems, I’ve taken the information below “on trust” from other sources. Please let me know if something below is inaccurate.
Windows
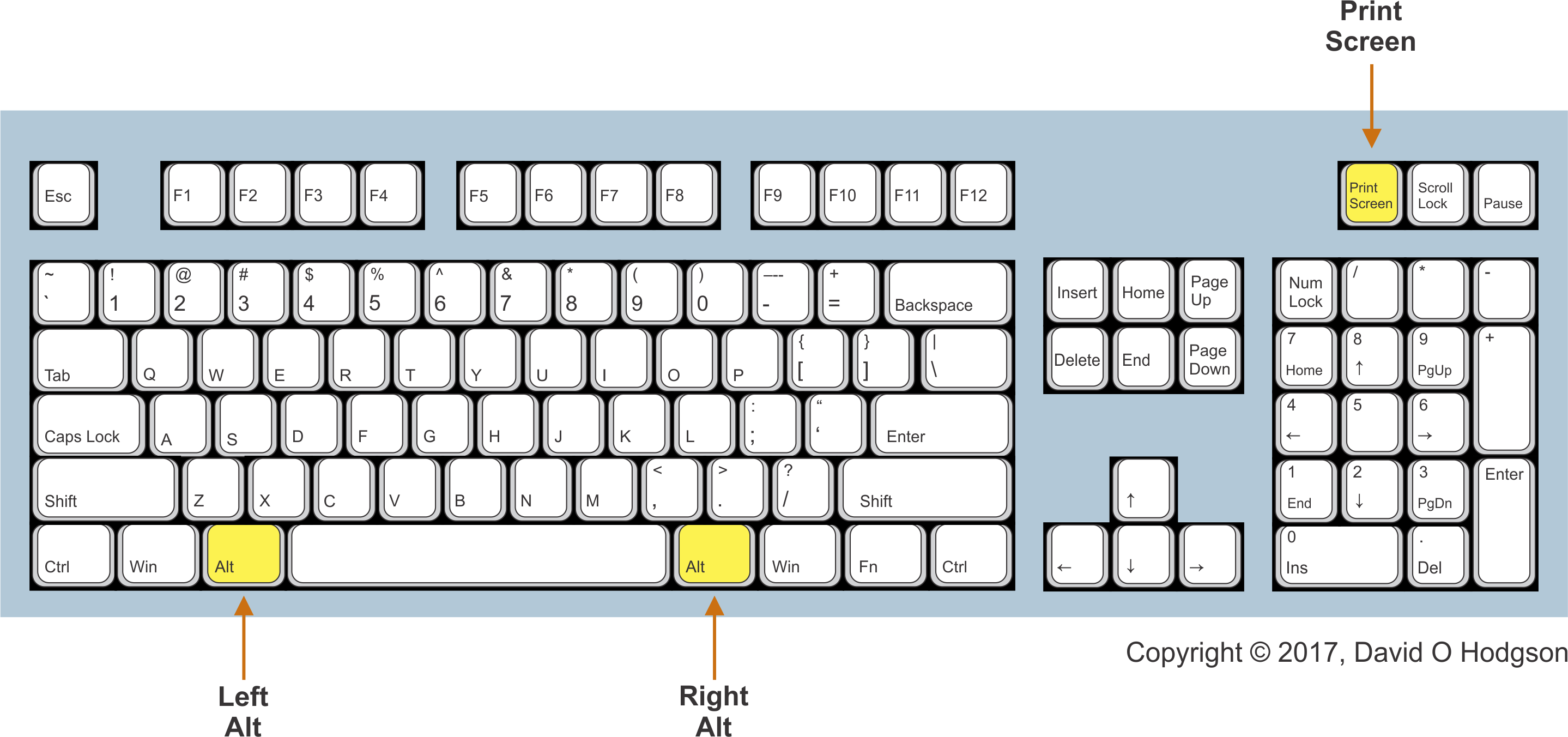
- To copy the entire screen area to the clipboard, press the Print Screen key. Note that, if your system has multiple screens, the captured bitmap will span all screens.
- To copy the active window to the clipboard, press the Alt+Print Screen keys simultaneously.
After pressing one of these key combinations, open a bitmap editing program (such as the built-in Paint program), then press Ctrl+V to paste the image into the program. You can then save the image as a bitmap file.
The positions of the Left Alt and Right Alt keys, and the Print Screen key, on a typical PC keyboard are as shown below. Typically, whenever a key combination requires use of the Alt key, you can press either the Left Alt or Right Alt keys.
Windows 10
One of the less well-known improvements in Windows 10 is that it offers some new screen capture capabilities, in addition to those described above that existed in previous versions of Windows.
- To save a copy of the entire screen to a file in the Screenshots folder, press the Win+Print Screen keys simultaneously.
- To save a copy of the active window to a file in the Screenshots folder, press the Win+Alt+Print Screen keys simultaneously.
- Video: for the first time, Windows offers a built-in screen recording capability, via the Game Bar. This feature is primarily intended for video game players, but it can also be used as a basic screen video recorder.
Apple (iOS)
I haven’t verified these instructions, which are provided on Apple’s iOS Support site, at:
https://support.apple.com/en-us/HT200289
- Press and hold the Sleep/Wake button on the top or side of your device.
- Immediately press and release the Home button.
- To find your screenshot, go to the Photos app > Albums and tap Camera Roll.
Android
If your smartphone is manufactured by Motorola, Samsung, or one of many others, then it probably uses Google’s Android operating system.
The obvious problem with screen capture in such devices is that they tend to have very few off-screen controls. If you tried to use software to perform a screen capture, then you would obscure part of the screen image that you want. Thus, screen capture usually has to be performed using some combination of the device’s available physical buttons.
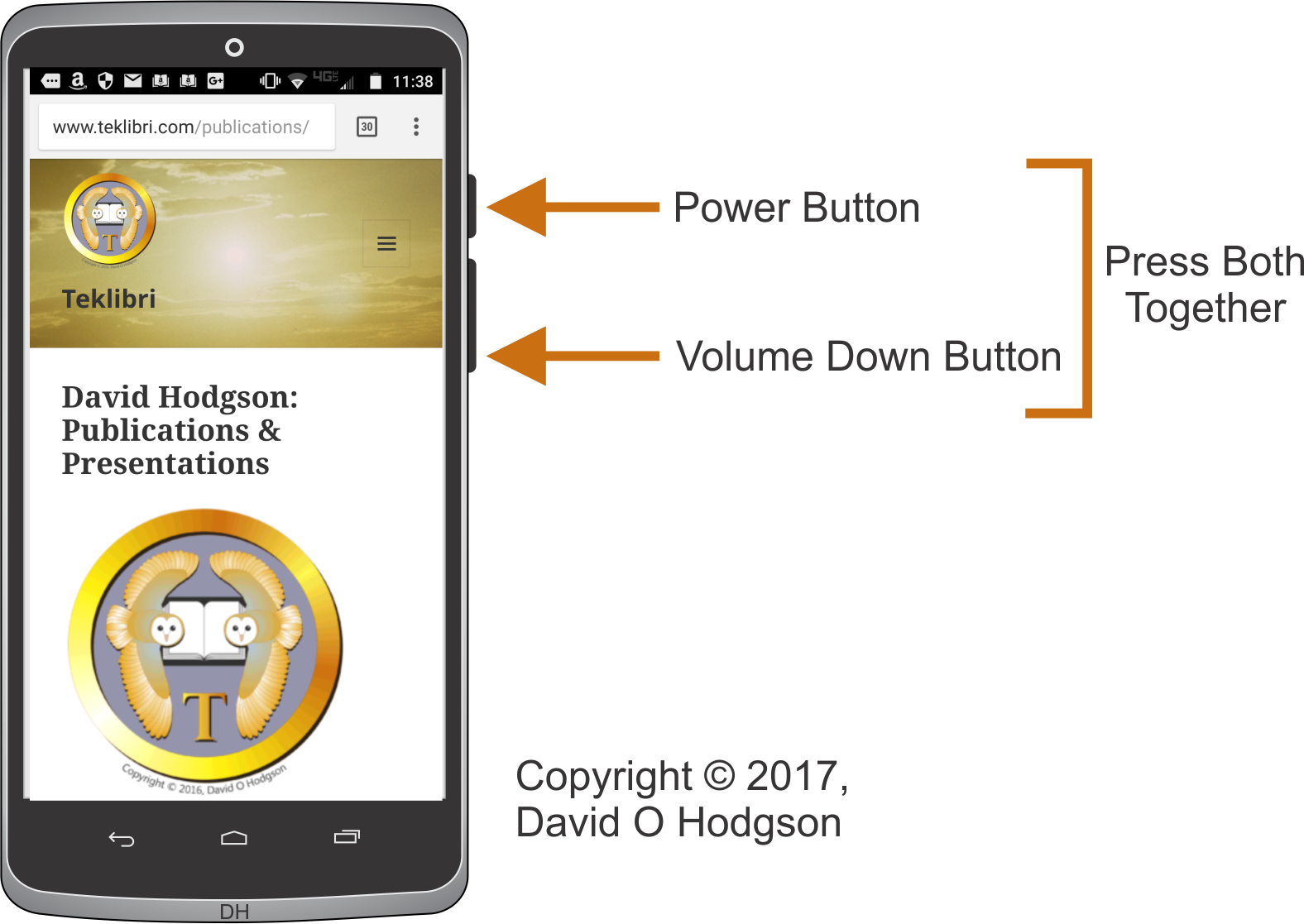
For devices from many manufacturers, you perform a screen capture by pressing the Power and Volume-Down buttons simultaneously.
This is actually quite tricky to do, and takes some practice.
If you don’t press both buttons at the same time, you’ll end up turning off the device!
HTC, LG, Motorola, Nexus, Sony
Press and hold Power and Volume-down buttons together. A bitmap containing the screen image is created in the Screenshot folder.
Alternatively, for Sony devices only, you can tap the Power button to access options to take a screenshot or screencast in the Power options menu.
Samsung
Press and hold Power and Home buttons together.
Alternatively, enable the ability to take a screenshot with a palm swipe in Settings, Motions & gestures, Palm swipe to capture.
Linux
The basic functionality is similar to that provided in Windows:
- Print Screen key: Copy the entire screen area to the clipboard. Note that, if your system has multiple screens, the bitmap will span all screens.
- Alt+Print Screen keys: Copy the active window to the clipboard.
Alternatively, you can use the Gnome-screenshot utility, which is part of the GNOME Desktop Environment.
Screen Capture Handling Pitfalls
Once you’ve obtained a “raw” screen capture bitmap, there are various ways that it’s likely that you’ll want to manipulate it. In general, you can use standard bitmap image processing tools and operations for screen captures. Standard tools include Microsoft Paint (included with Windows), Adobe Photoshop, Corel PhotoPaint, etc.
However, there are some additional considerations that can trap the unwary.
Including the Cursor
Generally, the screen cursor is not included in a screen capture. This is usually convenient, because you don’t want an arbitrarily positioned cursor in your image. In cases where you do want to show a cursor in the image, you can paste this in using a paint program later on.
Resizing the Image without Rescaling
I’ve seen many cases where a technical writer uses a screen-captured image in a help publication, but then resizes (reduces) the screen image to fit in some available space, and is surprised and disappointed when the resulting image appears “fuzzy” and sometimes unusable.
Here’s a small example where I’ve deliberately emphasized the poor results that occur when you try to reduce the size of a screen image containing text.
Here’s a dialog that I captured for documentation purposes:

But the dialog was too large to fit in my document, so I resized it to 50%:
Oh dear! As is obvious, the crisp text in the original image has now become so blurred that it’s almost unreadable. This would be of very limited value in documentation, and it definitely looks unprofessional. I’d be embarrassed to publish an image like this (except for the purposes of this counter-example).
The simple reality is that operating system manufacturers have put a lot of effort into optimizing the appearance of the screen at the intended size and resolution. These screens are not designed for resizing by interpolation methods.
Resizing without Interpolation
So, if I’m writing documentation and I simply have to make a screen capture image smaller, what can I do? One technique is to use the cut-and-paste features of your paint program to “squeeze up” the important parts of the dialog, so that the controls I want to discuss are still visible, but empty portions of the dialog are omitted. Here’s an example of that technique, applied to the dialog image above:
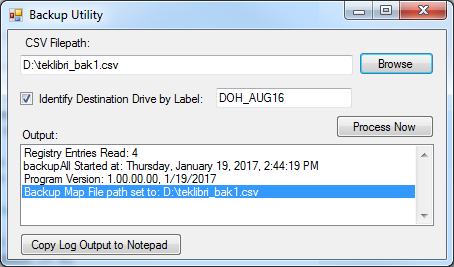
Notice that I moved the buttons at the right over to the left, and removed the “Test” button completely. I also moved the lower part of the dialog upwards, eliminating the blank gray area in the original. All the changes here were made in the paint program: I didn’t make any change to the display of the original dialog in the software. Because the dialog image has no noise, I was able to move around the elements seamlessly.
Here is the sequence of operations to resize the dialog as above:
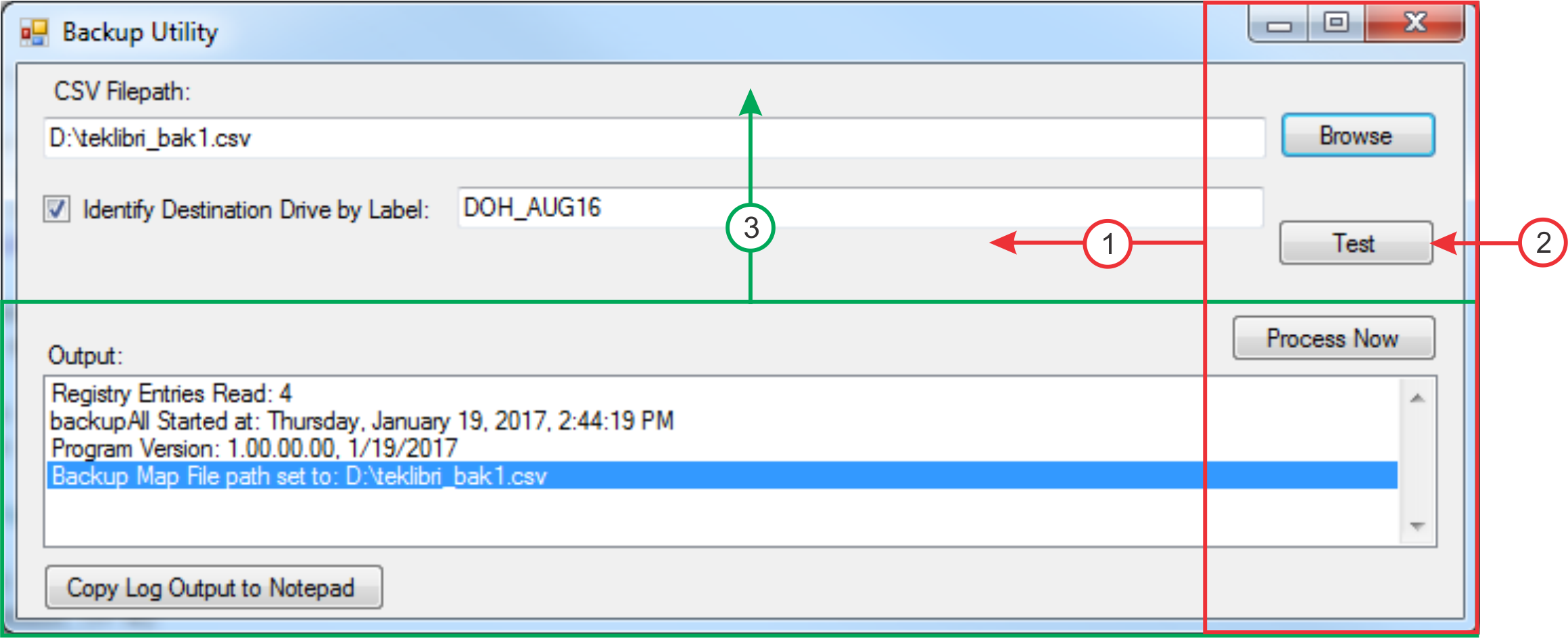
- Cut the red rectangle, move it left, and paste it.
- Paint out the Test button
- Cut the green rectangle, move it up, and paste it.
- Trim the entire image to its own new border.
Third-Party Tools
This article does not attempt to offer a comprehensive review of available third-party screen capture utilities. The following is a list of some commonly-used utilities, without any comment as to their quality or features.
Windows
SnagIt, Camtasia
Apple
SnagIt, Jing, LittleSnapper, Skitch
Android
Many “screen recorder” apps are available. See, for example, http://www.androidauthority.com/best-screen-recording-apps-600838/.
Linux
Shutter, Lookit
Summary
This article explained how the ability to capture an image of the screen, or (in some cases) a video of activity on-screen, is built into all modern operating systems. Even without third-party add-ons, you can capture and save screen images from any device.
Now you are armed with the knowledge of how to capture screen images from all your devices! You will never again have to offer up to Judge Judy the lame excuse that “I can’t show you that because my computer/tablet/phone broke”!